YOLOv3: An Incremental Improvement
Joseph Redmon, Ali Farhadi
模型比YOLOv2還要大因此更準,但仍然速度很快。
解決過去小物件時常漏抓的問題。
速度比其他detection任務模型還要快。
問題
- 很多資料集可能會有重疊類別,例如OpenImage資料集中有woman以及human的類別,過去採用softmax只能輸出一個類別可能會產生錯誤。
方法
- 對於重複類別的問題,採用Cross Entropy Loss。
- 跟Feature Paramid network概念一樣,在三種不同尺度下預測bounding box。
- COCO資料集,每個尺度預測三個Bounding Box。
- 淺層尺度的特徵圖會經過Upsampling(2×)與深層尺度特徵圖進行concatenation。這樣可以得到更多的影像資訊。
- 一樣有用K-Mean選擇Bounding Box的size:
- (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116 × 90),(156 × 198),(373 × 326)
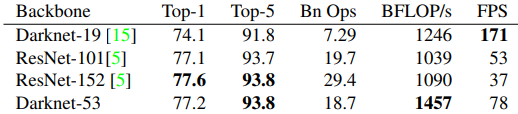
- 特徵提取層從原先的Darknet-19換成Darknet-53,仍效率很高。
Loss function
- Objectness score:利用logistic regression,如果Bounding Box與Ground truth object超過0.5,則為1。
訓練
- Multi-scale
- Data augmentaiton
- Batch normalization
試過沒效果的方法
- 添加Focal loss後mAP下降2%。
- logistic activation改成linear activation後mAP下降。
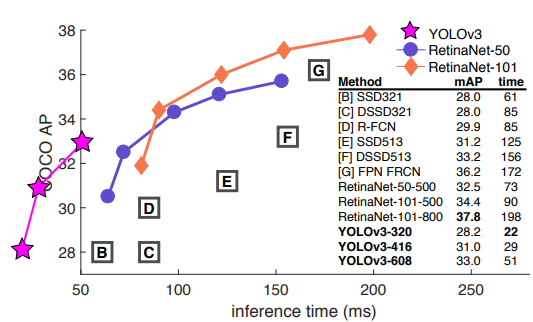
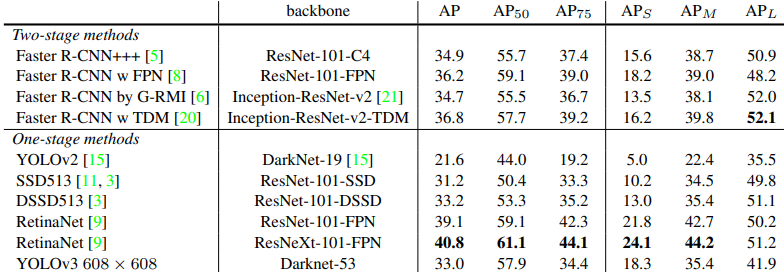
實驗結果
COCO資料集
文章使用之圖片擷取自該篇論文


 iThome鐵人賽
iThome鐵人賽